🌍 Accelerator Guide: Scientific Workflow Framework for Data to Indicators
📘 Objective of This Guide
This guide introduces a structured approach to executing scientific workflows using the Accelerator platform, with a particular focus on environmental, agricultural, and biodiversity-related data pipelines. The document is intended for technical practitioners — data scientists, modelers, and research engineers — who are looking to:
- Integrate public raw datasets into model-ready formats
- Validate and standardize model outputs
- Derive and inspect domain-specific indicators (e.g., biodiversity indicators)
- Version, reproduce, and share end-to-end simulations and transformations
Rather than covering tool-specific instructions, this guide articulates the intent and architecture of such workflows, setting the stage for deeper technical execution in companion documents.
🔍 What This Guide Covers
We highlight three representative use cases that collectively demonstrate the lifecycle of scientific data usage on Accelerator:
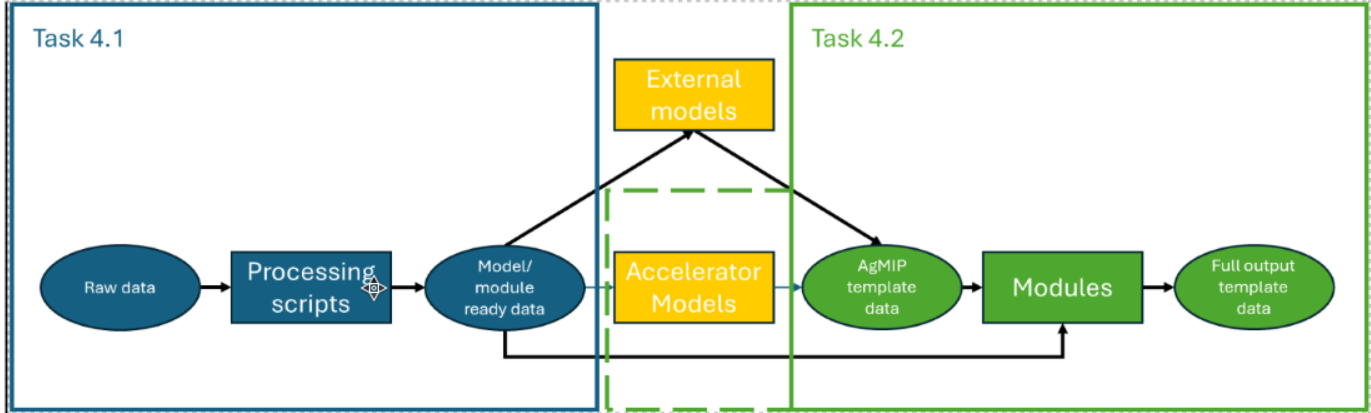
1. 📥 From Raw FAOSTAT Data to Model Input
This case focuses on how open-access data (e.g., FAOSTAT) can be downloaded, processed, and converted into formats such as GDX, suitable for models like GLOBIOM and CAPRI. It reflects early-stage data ingestion and transformation before simulation.
Objective: Standardize and prepare external data for scientific modeling pipelines.
➡️ Detailed implementation covered in: "Use Case 1: FAOSTAT to Model Input"
2. ✅ From Model Output to Validated Indicators
After model runs, we address how their outputs can be harmonized, validated, and passed through * indicator-generating modules* — with biodiversity indicators as a case in point. Outputs are checked for structural integrity and consistency.
Objective: Enhance model outputs with value-added derived metrics that are validated and interpretable.
➡️ Detailed implementation covered in: "Use Case 2: Harmonization and Indicators"
3. 🔁 Full Pipeline as Jobflow and Shared Model
Finally, we illustrate how the entire process — from ingestion to indicator — can be assembled into a single reproducible pipeline using Accelerator's jobflow orchestration. The jobflow can be hosted, parameterized, and shared with collaborators or the public, ensuring repeatable science.
Objective: Deploy the pipeline as a hosted scientific service with access controls and user-configurable parameters.
➡️ Detailed implementation covered in: "Use Case 3: Hosted Reproducible Jobflow"
🔄 Versioning for Trust and Transparency
A core principle in scientific data work is reproducibility. Accelerator supports this by enabling complete versioning of both code and data using integrated technologies:
- 📁 DVC-powered routines let you manage and push/pull datasets from remote storage, keeping versions synchronized
- 🧾 Git-integrated routines preserve the exact code version used in each job, including dependencies and configuration
- 🔐 Each run is traceable, including:
- Code hash
- Dataset mapping state
- Parameters used
- Runtime logs and duration
This ensures outputs can be audited, re-used, and trusted across time, people, and institutions.
🔚 Summary
This guide introduces the intent and scope of scientific workflow support in the Accelerator platform. Through three connected cases, we demonstrate how a modeler or researcher can:
- Operate across raw data ingestion, simulation, enrichment, and visualization
- Apply validation checkpoints at multiple stages
- Convert workflows into hosted and parameterized tools
- Enable reproducible science through built-in versioning
Each section is elaborated further in dedicated documents linked above.